

Now in Public Preview: Processing Files and Unstructured Data with Snowpark for Python
Snowflake
JULY 10, 2023
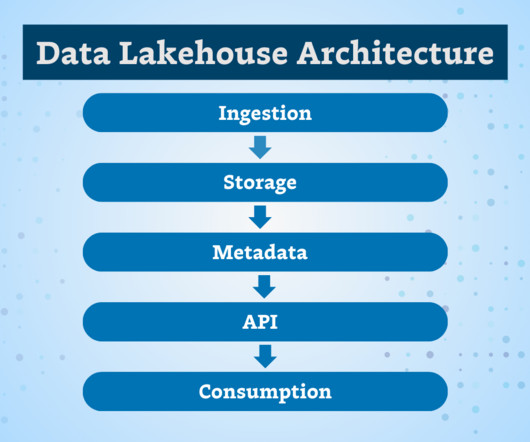
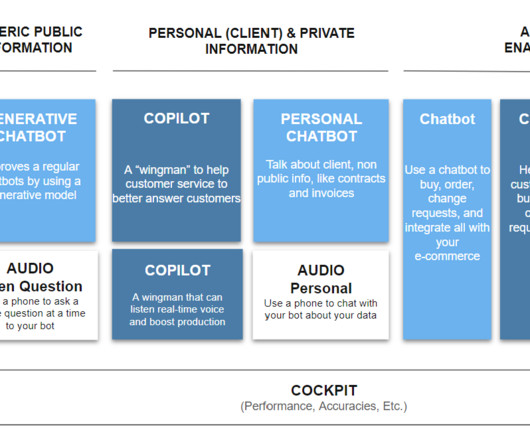
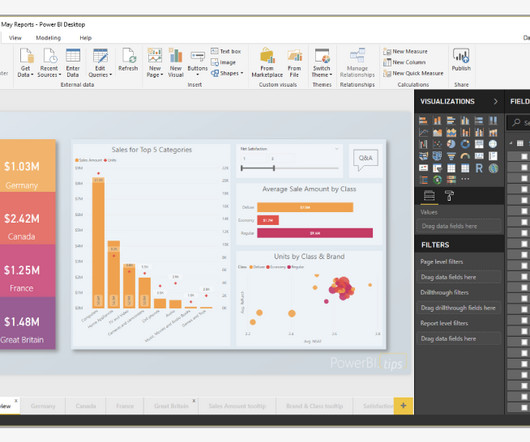
Announced at Summit, we’ve recently added to Snowpark the ability to process files programmatically, with Python in public preview and Java generally available. Data engineers and data scientists can take advantage of Snowflake’s fast engine with secure access to open source libraries for processing images, video, audio, and more.









































Let's personalize your content