

Supporting And Expanding The Arrow Ecosystem For Fast And Efficient Data Processing At Voltron Data
Data Engineering Podcast
NOVEMBER 27, 2022
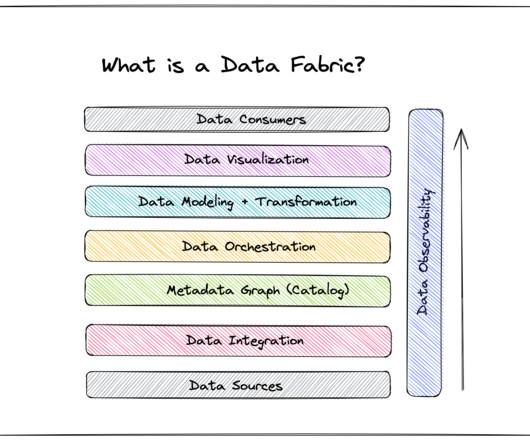
Summary The data ecosystem has been growing rapidly, with new communities joining and bringing their preferred programming languages to the mix. This has led to inefficiencies in how data is stored, accessed, and shared across process and system boundaries. Atlan is the metadata hub for your data ecosystem.









































Let's personalize your content