

Snowflake and the Pursuit Of Precision Medicine
Snowflake
NOVEMBER 29, 2023
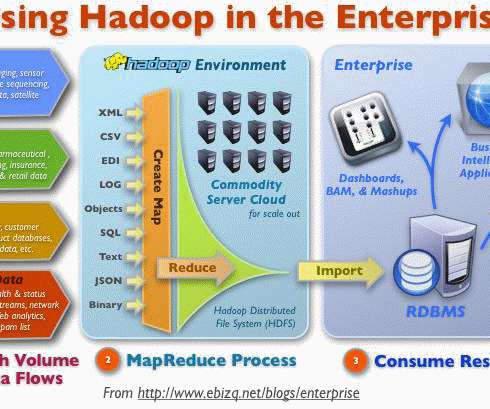
The data is there, it’s just not FAIR: Findable, Accessible, Interoperable and Reusable. Defining FAIR data and it’s applications for life sciences FAIR was a term coined in 2016 to help define good data management practices within the scientific realm. The principles emphasize machine-actionability (i.e.,


















Let's personalize your content