
1. Streamlining Membership Data Engineering at Netflix with Psyberg
Netflix Tech
NOVEMBER 14, 2023
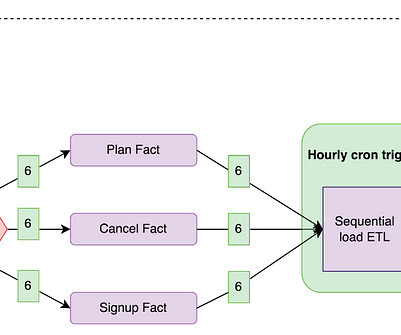
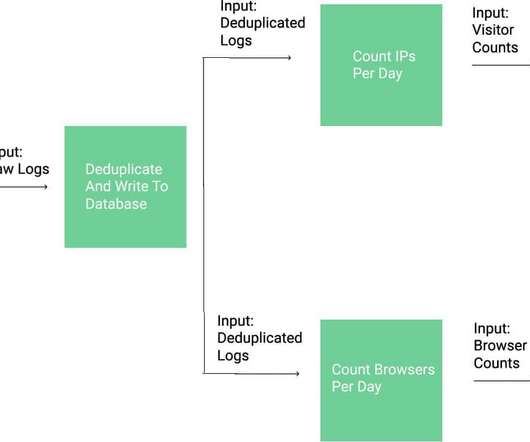
Types of late-arriving data Based on the structure of our upstream systems, we’ve classified late-arriving data into two categories, each named after the timestamps of the updated partition: Ways to process such data Our team previously employed some strategies to manage these scenarios, which often led to unnecessarily reprocessing unchanged data.










































Let's personalize your content