
Functional Data Engineering — a modern paradigm for batch data processing
Maxime Beauchemin
JANUARY 7, 2018
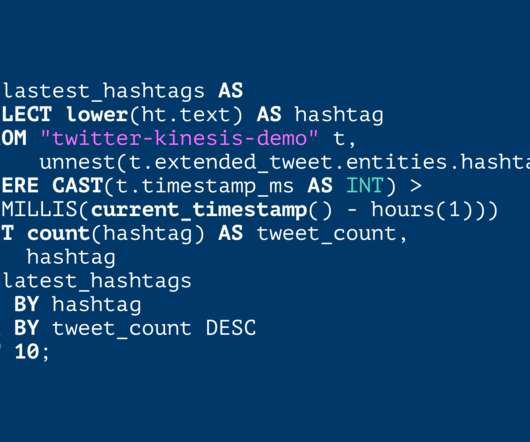
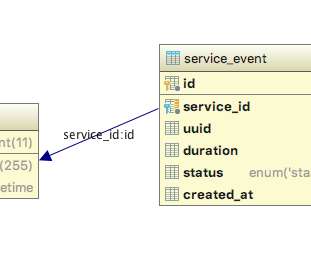
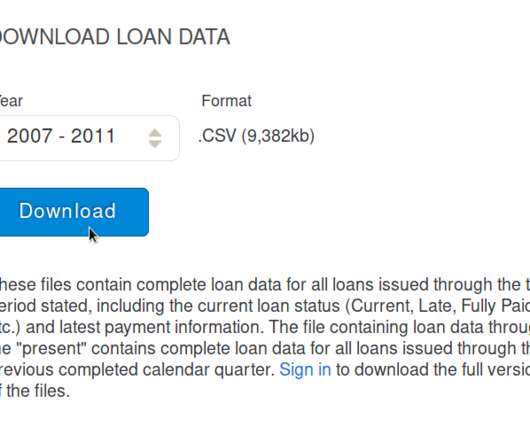
Batch data processing — historically known as ETL — is extremely challenging. It’s time-consuming, brittle, and often unrewarding. Not only that, it’s hard to operate, evolve, and troubleshoot. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. This post distills fragments of wisdom accumulated while working at Yahoo, Facebook, Airbnb and Lyft, with the perspective of well over a decade of data warehousing







































Let's personalize your content