
Table file formats are on the cloud
Waitingforcode
MARCH 9, 2023
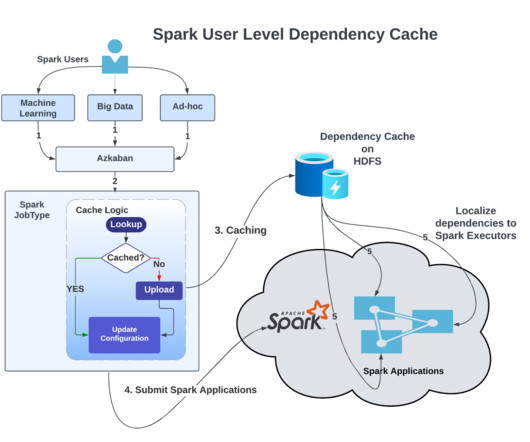
There is always a gap between a disruption in the data engineering industry and its integration on the cloud. It was not different for table file formats which have started gaining interest on AWS, Azure, GCP recently.
























Let's personalize your content