
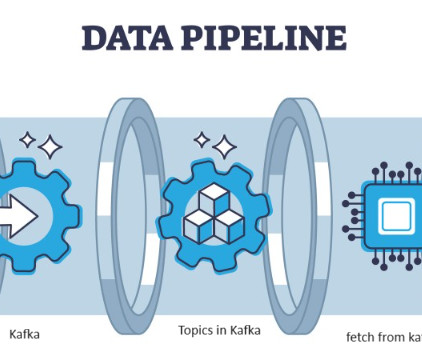
Kafka to MongoDB: Building a Streamlined Data Pipeline
Analytics Vidhya
FEBRUARY 28, 2024
Introduction Data is fuel for the IT industry and the Data Science Project in today’s online world. IT industries rely heavily on real-time insights derived from streaming data sources. Handling and processing the streaming data is the hardest work for Data Analysis.









































Let's personalize your content