

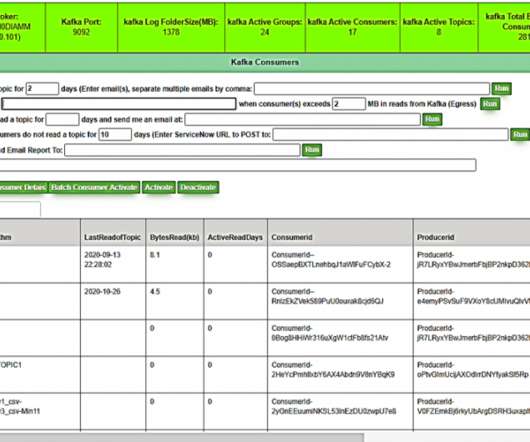
Transactional Machine Learning at Scale with MAADS-VIPER and Apache Kafka
Confluent
DECEMBER 11, 2020
This blog post shows how transactional machine learning (TML) integrates data streams with automated machine learning (AutoML), using Apache Kafka® as the data backbone, to create a frictionless machine learning […].












































Let's personalize your content