


Druid Deprecation and ClickHouse Adoption at Lyft
Lyft Engineering
NOVEMBER 29, 2023
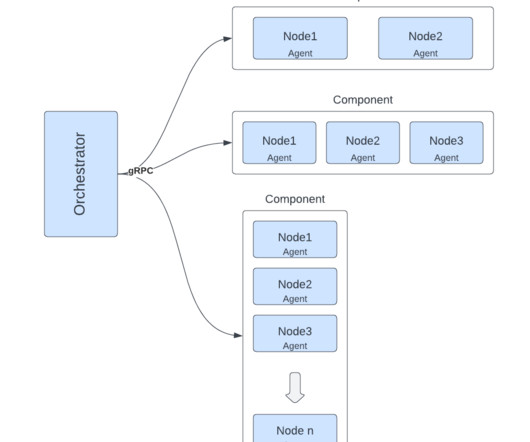
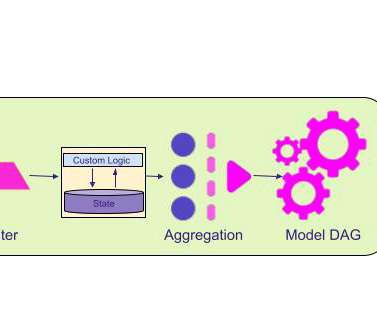
Introduction At Lyft, we have used systems like Apache ClickHouse and Apache Druid for near real-time and sub-second analytics. In this particular blog post, we explain how Druid has been used at Lyft and what led us to adopt ClickHouse for our sub-second analytic system. ioConfig: Kafka server info, topic names, etc.


































Let's personalize your content