

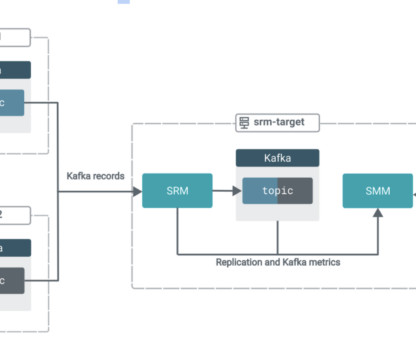
Using Streams Replication Manager Prefixless Replication for Kafka Topic Aggregation
Cloudera
FEBRUARY 28, 2024
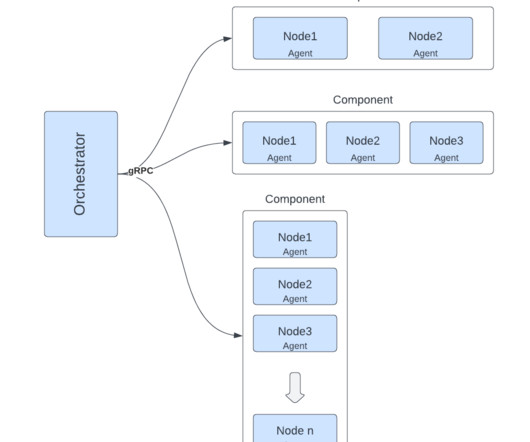
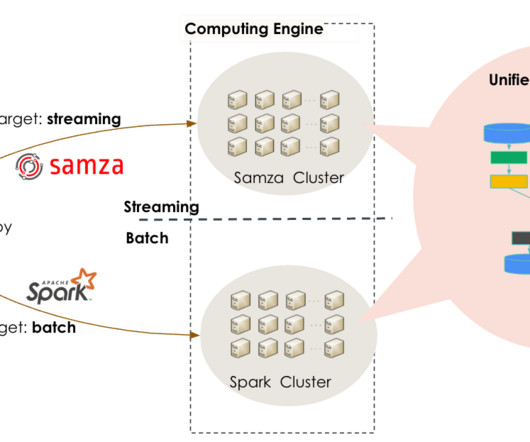
For example, if there are separate clusters, and there are topics with the same purpose in the different clusters, then it is useful to aggregate the content into one topic. This blog post walks you through how you can use prefixless replication with Streams Replication Manager (SRM) to aggregate Kafka topics from multiple sources.









































Let's personalize your content