
Scaling Uber’s Apache Hadoop Distributed File System for Growth
Uber Engineering
APRIL 5, 2018
Three years ago, Uber Engineering adopted Hadoop as the storage ( HDFS ) and compute ( YARN ) infrastructure for our organization’s big data analysis.

Uber Engineering
APRIL 5, 2018
Three years ago, Uber Engineering adopted Hadoop as the storage ( HDFS ) and compute ( YARN ) infrastructure for our organization’s big data analysis.

Knowledge Hut
DECEMBER 28, 2023
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Knowledge Hut
APRIL 25, 2024
In this blog post, we will discuss such technologies. If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. Spark is a fast and general-purpose cluster computing system.

Christophe Blefari
JANUARY 20, 2024
Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a data warehouse at the center. In order to understand today's data engineering I think that this is important to at least know Hadoop concepts and context and computer science basics.

Knowledge Hut
MAY 2, 2024
Apache Spark is a fast and general-purpose cluster computing system. In this article, we will cover the installation procedure of Apache Spark on the Ubuntu operating system. Prerequisites This guide assumes that you are using Ubuntu and that Hadoop 2.7 is installed in your system. System requirements Ubuntu OS Installed.

Jesse Anderson
DECEMBER 12, 2022
Google looked over the expanse of the growing internet and realized they’d need scalable systems. Doug Cutting took those papers and created Apache Hadoop in 2005. They were the first companies to commercialize open source big data technologies and pushed the marketing and commercialization of Hadoop.

Cloudera
DECEMBER 14, 2017
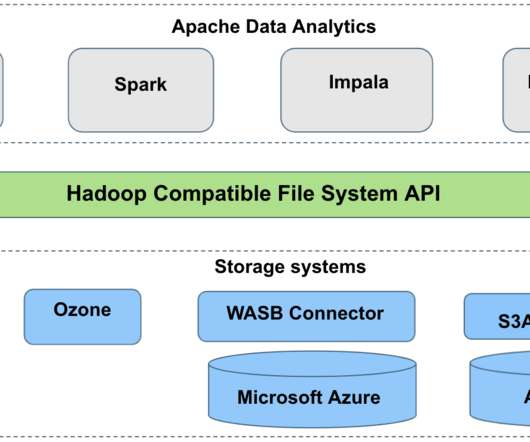
The Apache Hadoop community recently released version 3.0.0 GA , the third major release in Hadoop’s 10-year history at the Apache Software Foundation. alpha2 on the Cloudera Engineering blog, and 3.0.0 Improved support for cloud storage systems like S3 (with S3Guard ), Microsoft Azure Data Lake, and Aliyun OSS.

Expert insights. Personalized for you.




































Let's personalize your content