

How to learn data engineering
Christophe Blefari
JANUARY 20, 2024
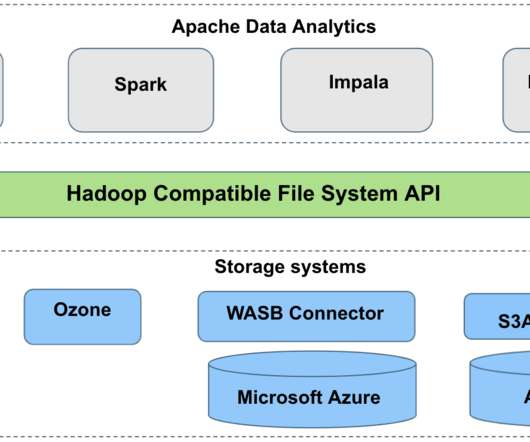
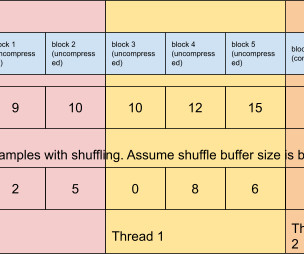
Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a data warehouse at the center. In order to understand today's data engineering I think that this is important to at least know Hadoop concepts and context and computer science basics.












































Let's personalize your content