


An AI Chat Bot Wrote This Blog Post …
DataKitchen
DECEMBER 9, 2022
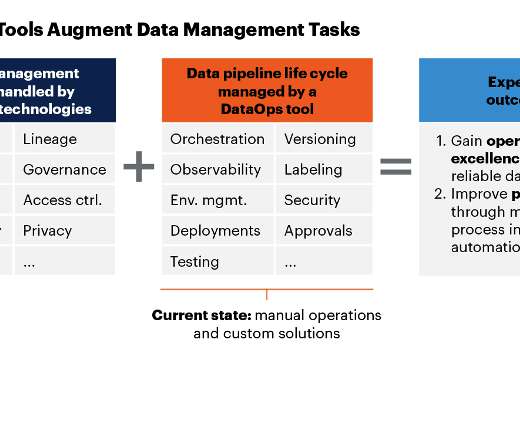
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their data analytics processes. The goal of DataOps is to help organizations make better use of their data to drive business decisions and improve outcomes.




































Let's personalize your content