

DataOps Architecture: 5 Key Components and How to Get Started
Databand.ai
AUGUST 30, 2023
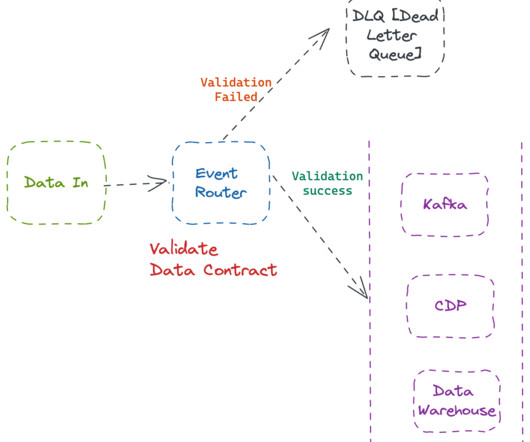
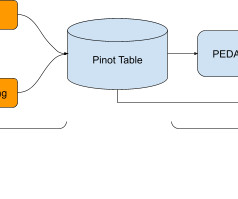
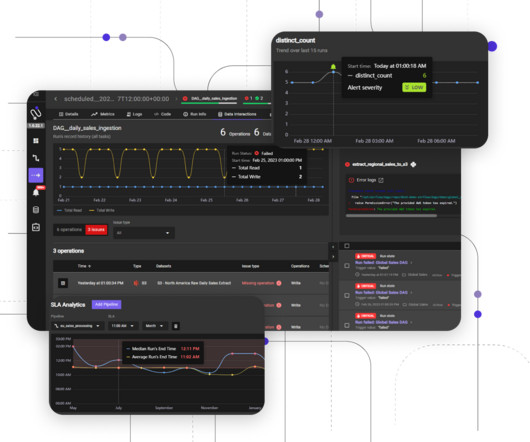
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various data workflows.


























Let's personalize your content