

Data Reprocessing Pipeline in Asset Management Platform @Netflix
Netflix Tech
MARCH 10, 2023
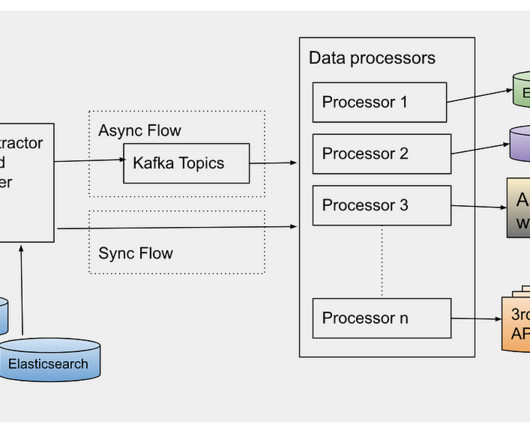
During this evolution, quite often we receive requests to update the existing assets metadata or add new metadata for the new features added. This pattern grows over time when we need to access and update the existing assets metadata.











Let's personalize your content