

DataOps Architecture: 5 Key Components and How to Get Started
Databand.ai
AUGUST 30, 2023
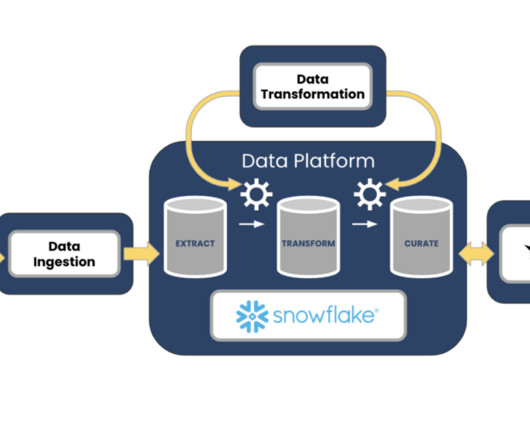
DataOps Architecture: 5 Key Components and How to Get Started Ryan Yackel August 30, 2023 What Is DataOps Architecture? DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. As a result, they can be slow, inefficient, and prone to errors.




































Let's personalize your content