

From Big Data to Better Data: Ensuring Data Quality with Verity
Lyft Engineering
OCTOBER 3, 2023
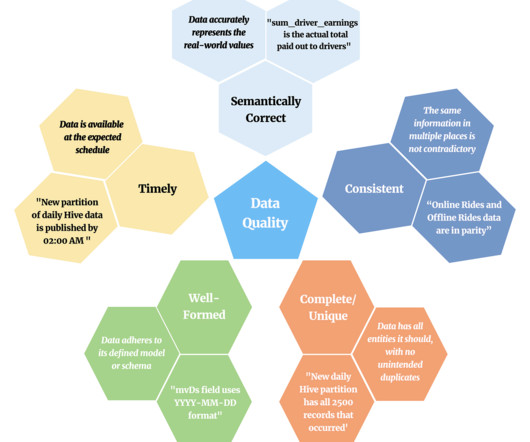
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. Analytic Event Lifecycle Lyft reads and writes petabytes of data every day to Hive — much of it coming from analytic events. Science and product teams can also create checks and orchestrate them on a fixed schedule.
























Let's personalize your content