

Fast Copy-On-Write within Apache Parquet for Data Lakehouse ACID Upserts
Uber Engineering
JUNE 29, 2023
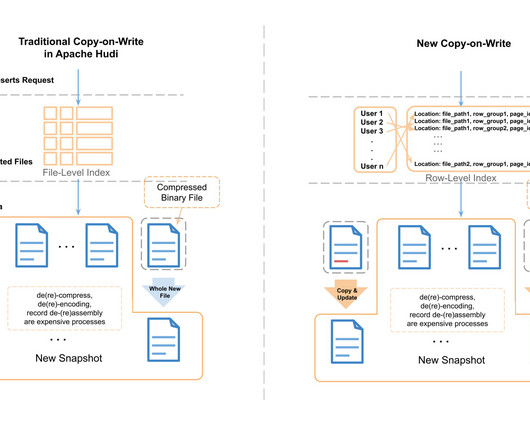
Experience the power of row-level secondary indexing in Apache Parquet, enabling 3-20X faster upserts and unlocking new possibilities for efficient table ACID operations in today’s Lakehouse architecture.














































Let's personalize your content