
Fivetran Supports the Automation of the Modern Data Lake on Amazon S3
phData: Data Engineering
APRIL 4, 2023
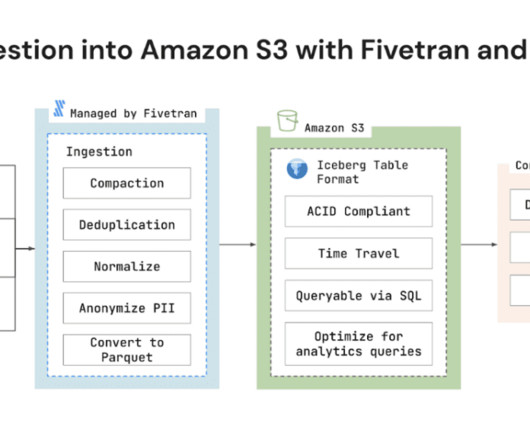
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.

















Let's personalize your content