
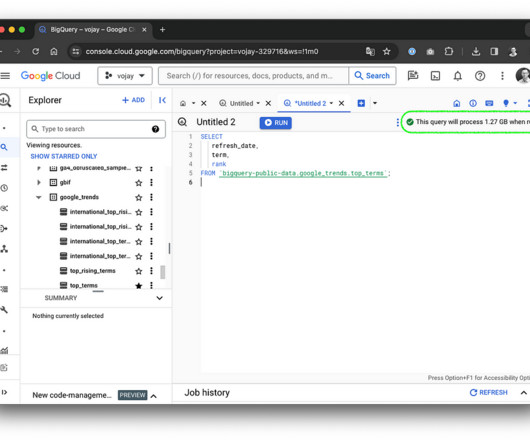
A Definitive Guide to Using BigQuery Efficiently
Towards Data Science
MARCH 5, 2024
Summary ∘ Embrace data modeling best practices ∘ Master data operations for cost-effectiveness ∘ Design for efficiency and avoid unnecessary data persistence Disclaimer : BigQuery is a product which is constantly being developed, pricing might change at any time and this article is based on my own experience. in europe-west3.











































Let's personalize your content