

Experts Share the 5 Pillars Transforming Data & AI in 2024
Monte Carlo
JANUARY 23, 2024
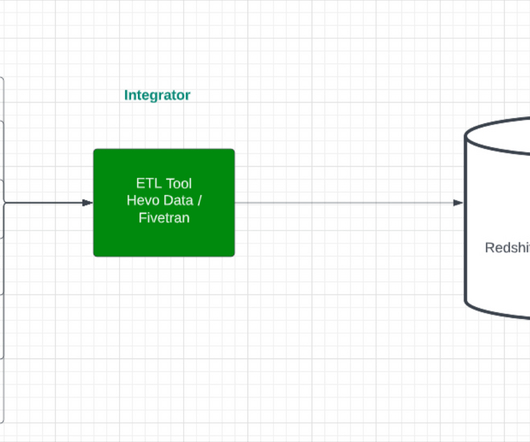
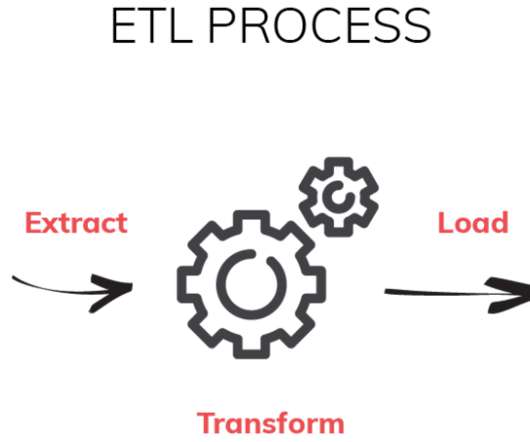
Gen AI can whip up serviceable code in moments — making it much faster to build and test data pipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. But what does that mean for the roles of data engineers and data scientists going forward?











































Let's personalize your content