


Apache Spark Use Cases & Applications
Knowledge Hut
MAY 2, 2024
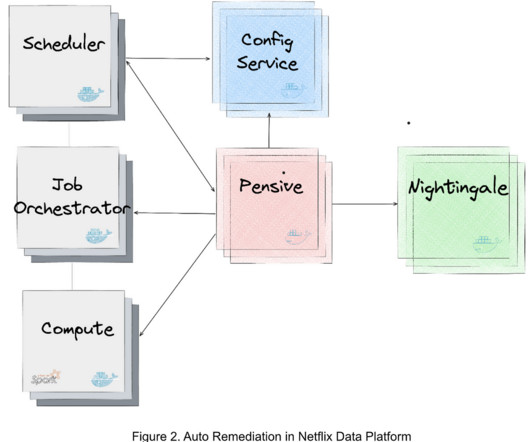
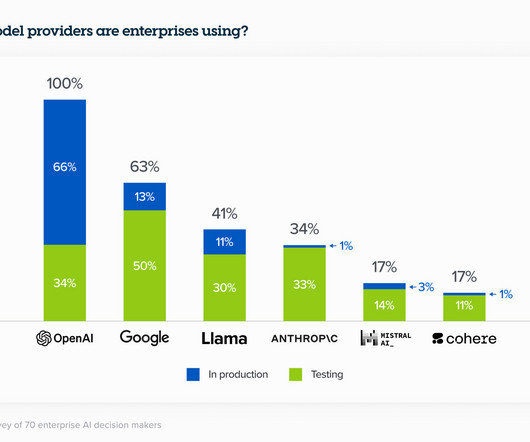
Apache Spark was developed by a team at UC Berkeley in 2009. Since then, Apache Spark has seen a very high adoption rate from top-notch technology companies like Google, Facebook, Apple, Netflix etc. According to marketanalysis.com survey, the Apache Spark market worldwide will grow at a CAGR of 67% between 2019 and 2022.














































Let's personalize your content