
Revolutionizing Real-Time Streaming Processing: 4 Trillion Events Daily at LinkedIn
LinkedIn Engineering
OCTOBER 19, 2023
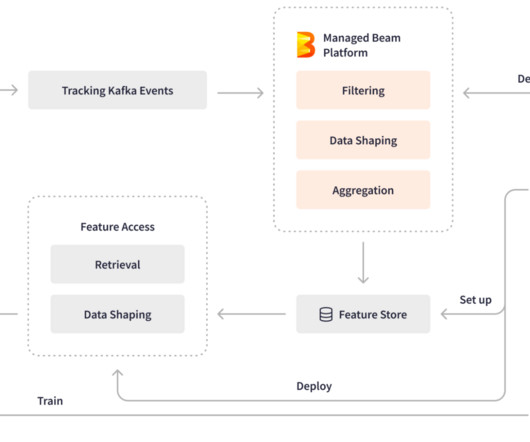
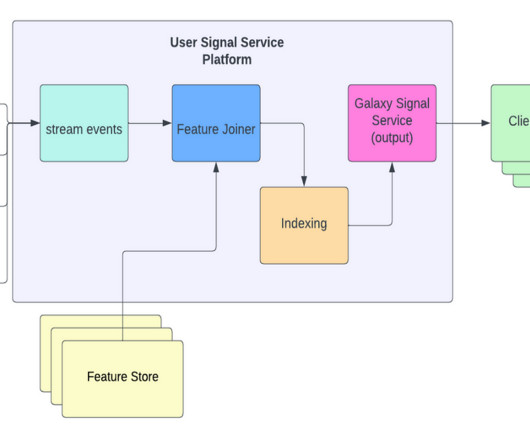
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.













Let's personalize your content