AWS RDS PostgreSQL Setup
Start Data Engineering
JULY 18, 2020
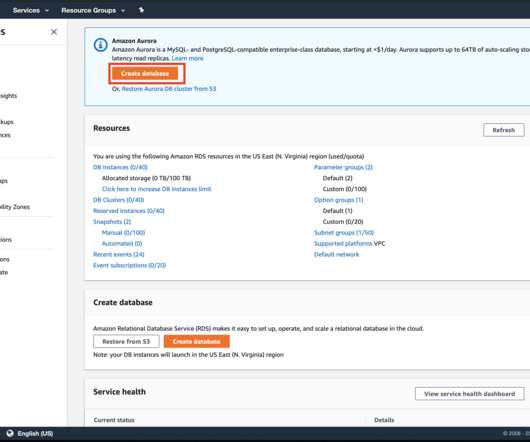
RDS AWS RDS is a managed service provided by AWS to run a relational database. We will see how to setup a postgres instance using AWS RDS. Log in to your AWS account. Go to Services -> RDS Click on Create Database, In the Create Database prompt, choose Standard Create option with PostgreSQL as engine type. In the Template section choose Free Tier and type in a DB Identifier, Master username and Master password.


























Let's personalize your content