
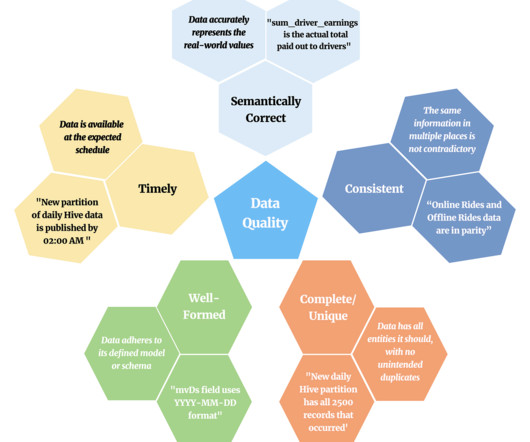
What is Data Enrichment? Best Practices and Use Cases
Precisely
OCTOBER 5, 2023
How much data is your business generating each day? While answers will vary by organization, chances are there’s one commonality: it’s more data than ever before. But what do you do with all that data? According to the 2023 Data Integrity Trends and Insights Report , published in partnership between Precisely and Drexel University’s LeBow College of Business, 77% of data and analytics professionals say data-driven decision-making is the top goal of their data programs.





































Let's personalize your content