
Designing a "low-effort" ELT system, using stitch and dbt
Start Data Engineering
JULY 11, 2020
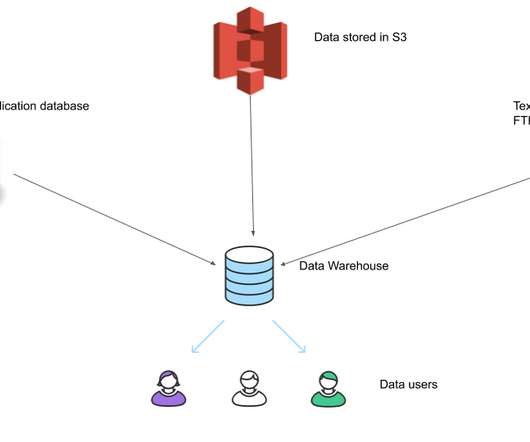
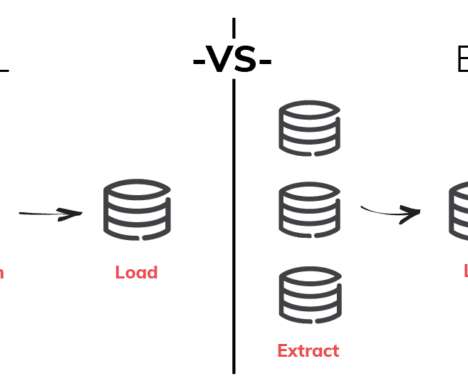
Intro A very common use case in data engineering is to build a ETL system for a data warehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application (..)














Let's personalize your content