
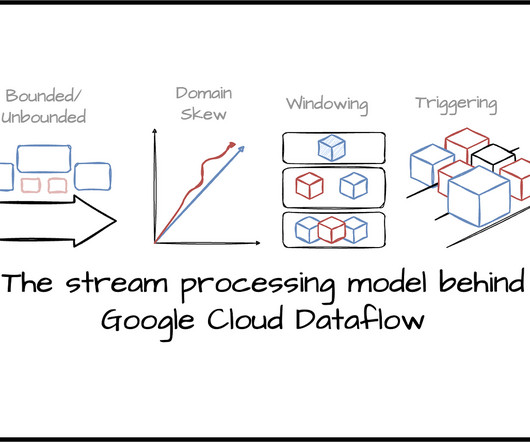
The Stream Processing Model Behind Google Cloud Dataflow
Towards Data Science
APRIL 30, 2024
Balancing correctness, latency, and cost in unbounded data processing Image created by the author. Intro Google Dataflow is a fully managed data processing service that provides serverless unified stream and batch data processing. Apache Beam lets users define processing logic based on the Dataflow model.


















Let's personalize your content