

Data News — Week 24.11
Christophe Blefari
MARCH 15, 2024
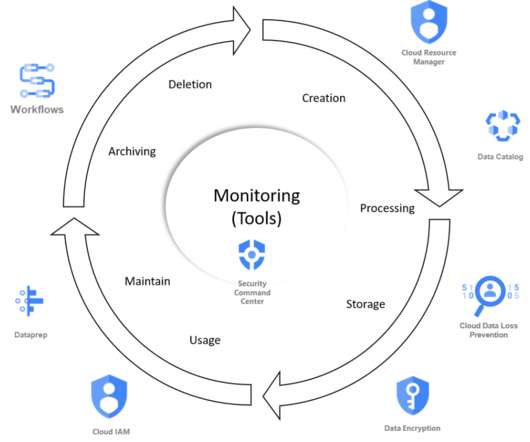
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. Matthaus gives the dlt vision about creating the foundation for developers to be able to create sources in a wink creating a large ecosystem of APIs datasets easily maintainable. This is Croissant.






































Let's personalize your content