

Reflections On Designing A Data Platform From Scratch
Data Engineering Podcast
FEBRUARY 27, 2022
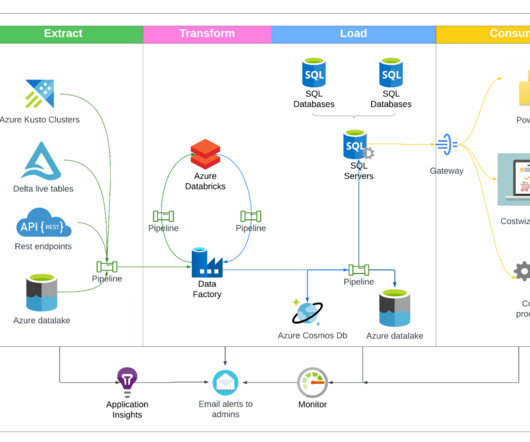
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. I’m your host, Tobias Macey, and today I’m sharing the approach that I’m taking while designing a data platform Interview Introduction How did you get involved in the area of data management?










































Let's personalize your content