

Top Data Catalog Tools
Monte Carlo
FEBRUARY 26, 2024
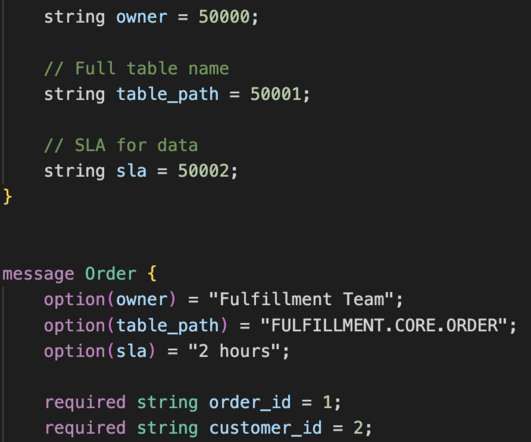
A data catalog is a constantly updated inventory of the universe of data assets within an organization. It uses metadata to create a picture of the data, as well as the relationships between data assets of diverse sources, and the processing that takes place as data moves through systems.











Let's personalize your content