
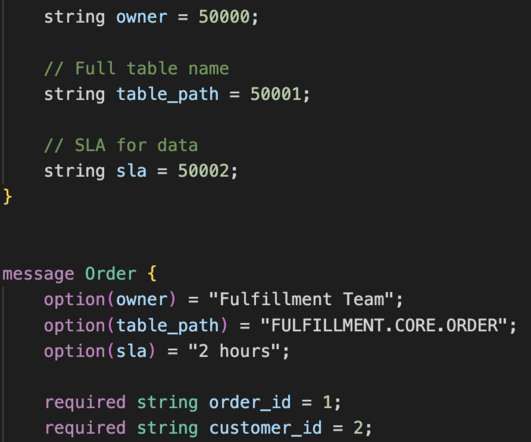
Implementing Data Contracts in the Data Warehouse
Monte Carlo
JANUARY 25, 2023
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your data warehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.












Let's personalize your content