
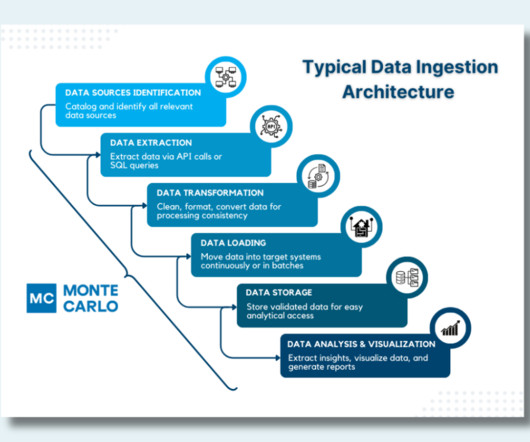
How to Design a Modern, Robust Data Ingestion Architecture
Monte Carlo
MAY 28, 2024
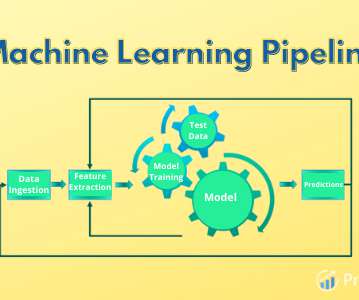
A data ingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process.













































Let's personalize your content