

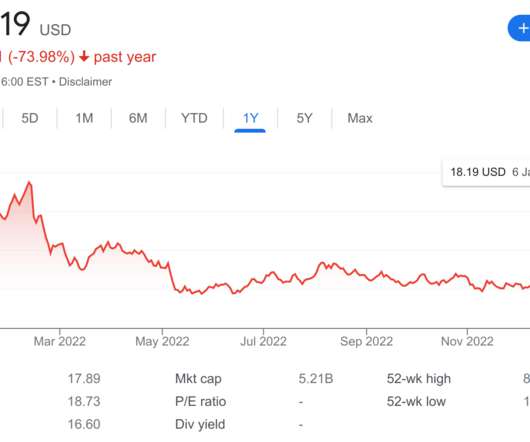
Analysis of Confluent Buying Immerok
Jesse Anderson
JANUARY 9, 2023
I started a Twitter thread with some of my initial thoughts, but I want to write a post giving more analysis and opinions. I think it’s quite telling that even the announcement doesn’t get ksqlDB’s name right. Since Kafka Streams is part of the Apache project, I don’t see it going away as quickly.














































Let's personalize your content