

Digital Transformation is a Data Journey From Edge to Insight
Cloudera
JANUARY 20, 2021
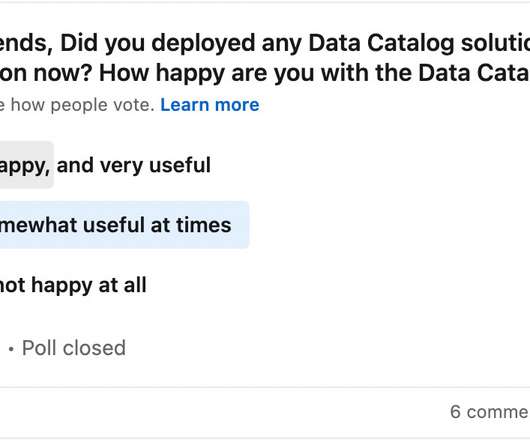
The missing chapter is not about point solutions or the maturity journey of use cases, the missing chapter is about the data, it’s always been about the data, and most importantly the journey data weaves from edge to artificial intelligence insight. . Data Collection Challenge. Factory ID. Machine ID.



























Let's personalize your content