

An Engineering Guide to Data Quality - A Data Contract Perspective - Part 2
Data Engineering Weekly
MAY 16, 2023
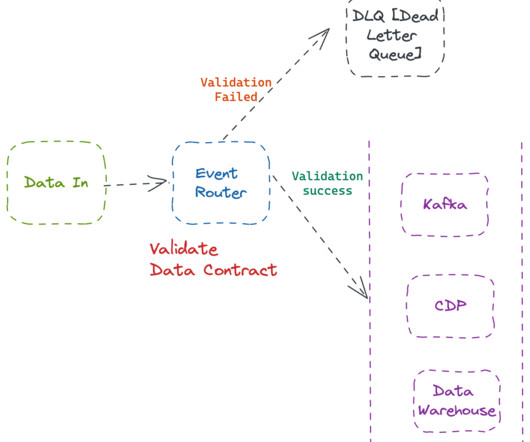
In the first part of this series, we talked about design patterns for data creation and the pros & cons of each system from the data contract perspective. I won’t bore you with the importance of data quality in the blog. The Fronting Kafka pattern follows a two-cluster approach. Why is Data Quality Expensive?




















Let's personalize your content