
Consulting Case Study: Recommender Systems
WeCloudData
OCTOBER 19, 2021
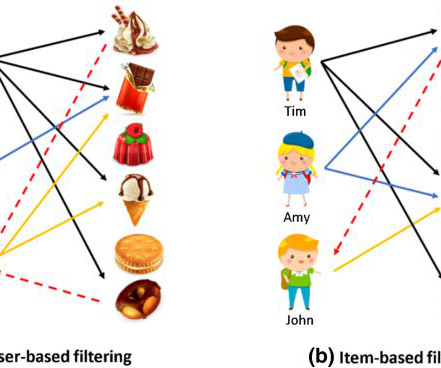
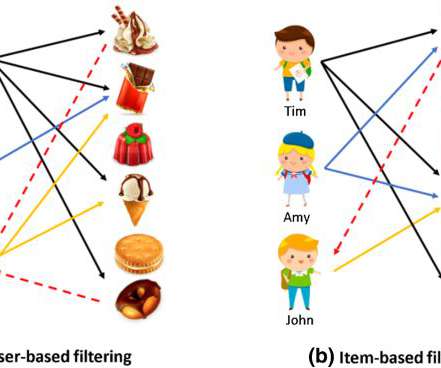
Next, in order for the client to leverage their collected user clickstream data to enhance the online user experience, the WeCloudData team was tasked with developing recommender system models whereby users can receive more personalized article recommendations.



















Let's personalize your content