

DEW #124: State of Analytics Engineering, ChatGPT, LLM & the Future of Data Consulting, Unified Streaming & Batch Pipeline, and Kafka Schema Management
Data Engineering Weekly
APRIL 28, 2023
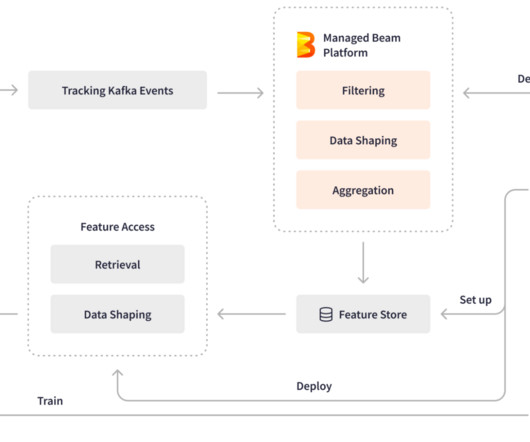
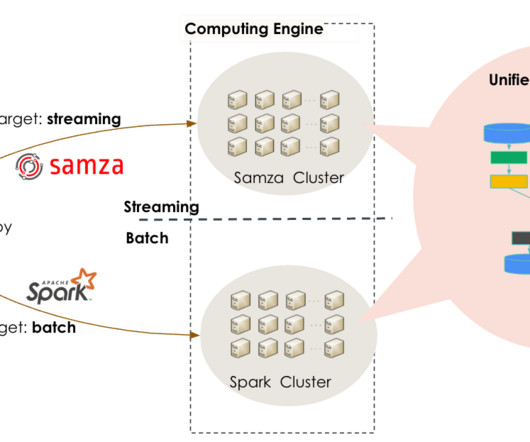
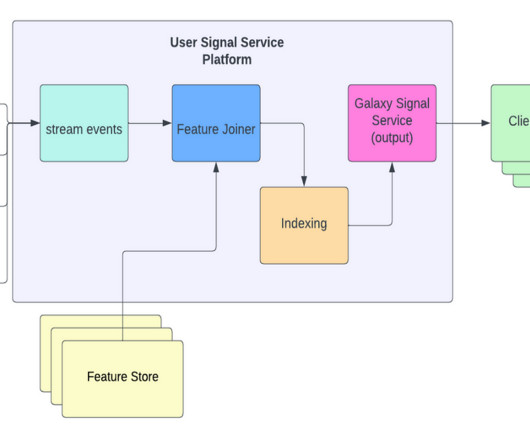
🤺🤺🤺🤺🤺🤺 [link] LinkedIn: Unified Streaming And Batch Pipelines At LinkedIn: Reducing Processing time by 94% with Apache Beam One of the curses of adopting Lambda Architecture is the need for rewriting business logic in both streaming and batch pipelines.


















Let's personalize your content