

Data Pipeline Architecture: Understanding What Works Best for You
Ascend.io
JULY 28, 2023
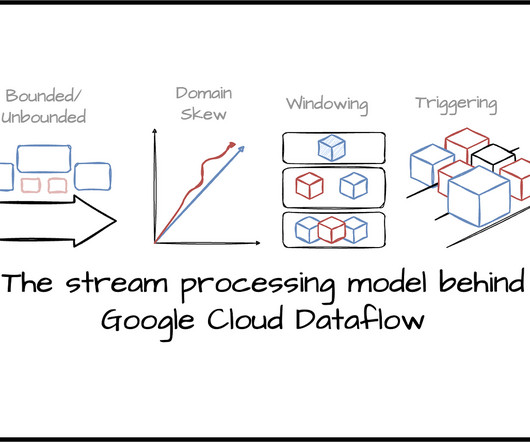
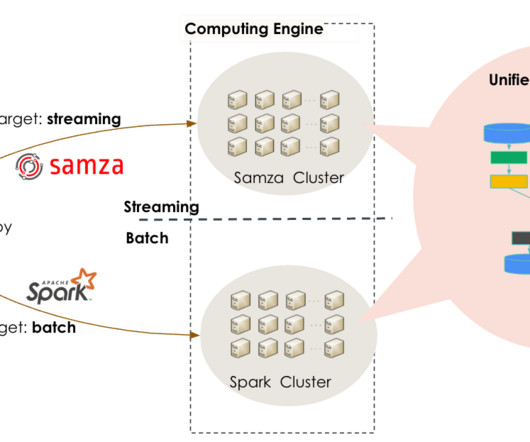
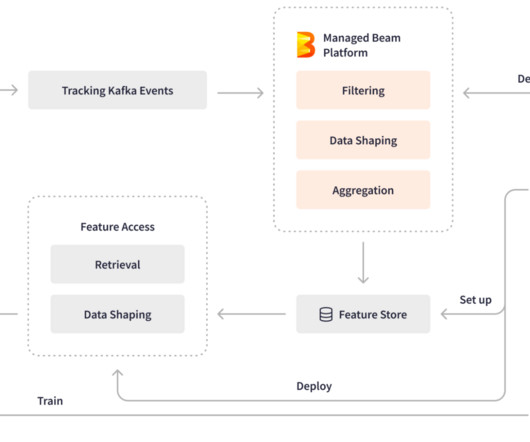
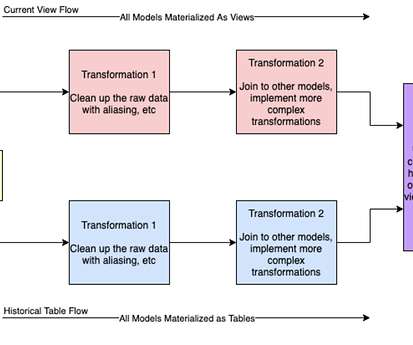
As companies become more data-driven, the scope and complexity of data pipelines inevitably expand. Without a well-planned architecture, these pipelines can quickly become unmanageable, often reaching a point where efficiency and transparency take a backseat, leading to operational chaos. What Is Data Pipeline Architecture?












Let's personalize your content