

Handling Bursty Traffic in Real-Time Analytics Applications
Rockset
MAY 12, 2022
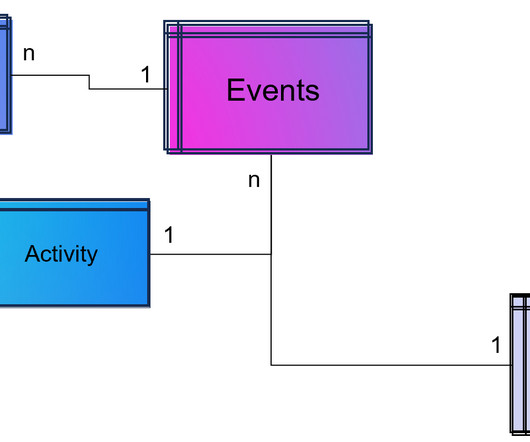
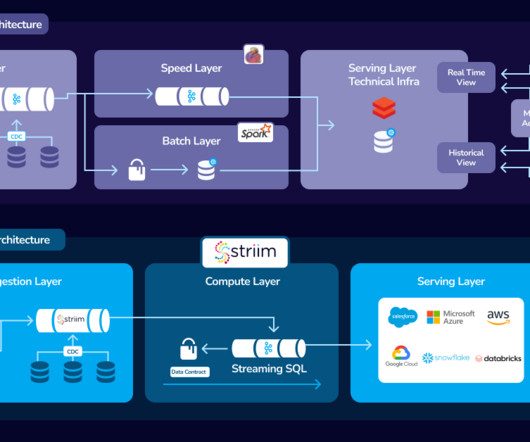
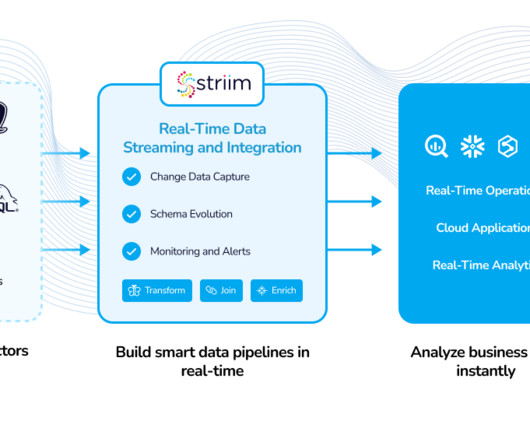
Maintaining two data processing paths creates extra work for developers who must write and maintain two versions of code, as well as greater risk of data errors. Developers and data scientists also have little control over the streaming and batch data pipelines. No need to overprovision in advance.
























Let's personalize your content