

How Snowflake Enhanced GTM Efficiency with Data Sharing and Outreach Customer Engagement Data
Snowflake
APRIL 9, 2024
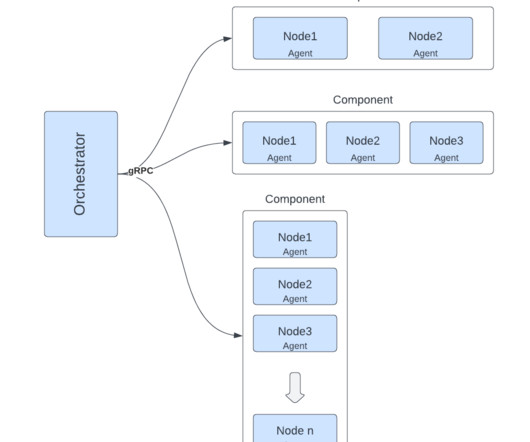
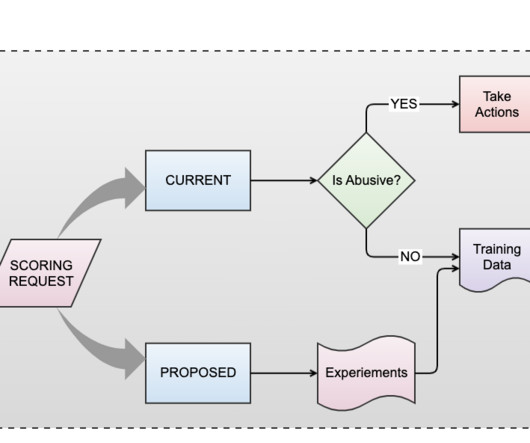
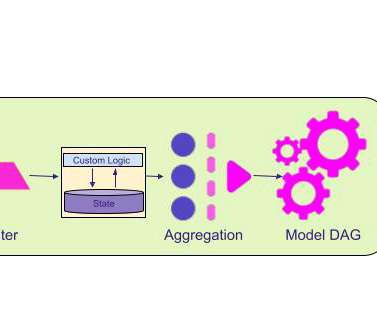
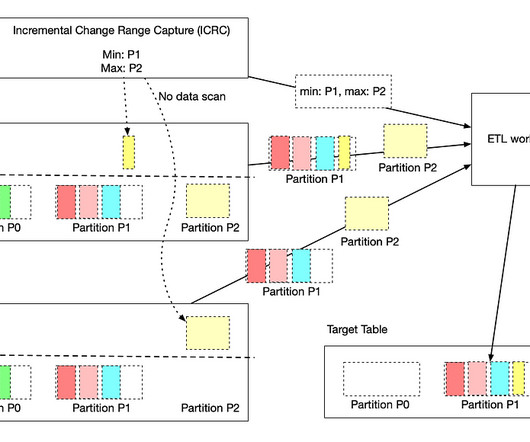
To improve go-to-market (GTM) efficiency, Snowflake created a bi-directional data share with Outreach that provides consistent access to the current version of all our customer engagement data. In this blog, we’ll take a look at how Snowflake is using data sharing to benefit our SDR teams and marketing data analysts.


































Let's personalize your content