
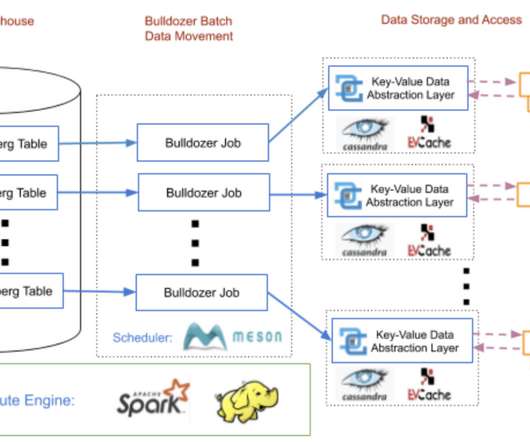
Bulldozer: Batch Data Moving from Data Warehouse to Online Key-Value Stores
Netflix Tech
OCTOBER 27, 2020
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as data warehouse tables in AWS S3.

















Let's personalize your content