
Improved Ascend for Databricks, New Lineage Visualization, and Better Incremental Data Ingestion
Ascend.io
DECEMBER 19, 2022
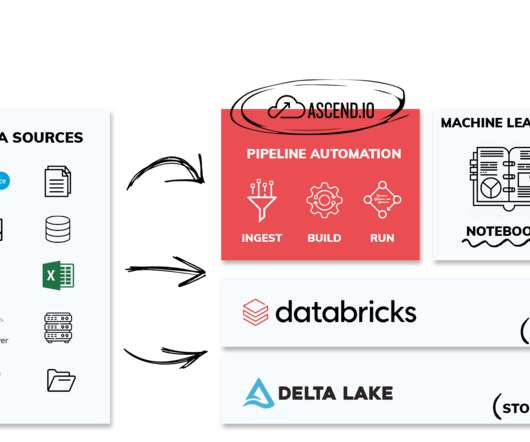
Improved Support for Databricks To highlight our improved Databricks capabilities, our re:Invent booth was next to theirs, and we chose to power our demos with their Lakehouse. More and more customers are dramatically accelerating their time to value with Databricks data pipelines by leveraging Ascend automation.


































Let's personalize your content