

Building A Data Governance Bridge Between Cloud And Datacenters For The Enterprise At Privacera
Data Engineering Podcast
MARCH 27, 2022
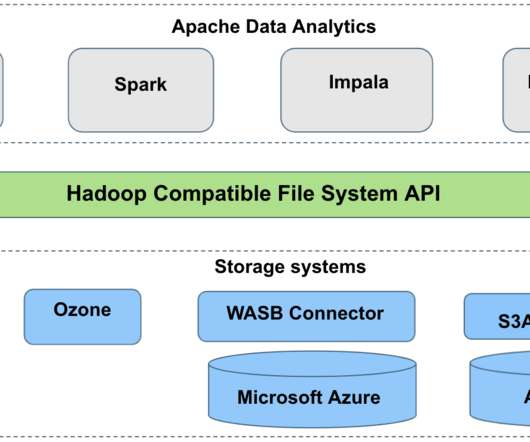
The growing prominence of cloud and hybrid environments in data management adds additional stress to an already complex endeavor. Privacera is an enterprise grade solution for cloud and hybrid data governance built on top of the robust and battle tested Apache Ranger project. Can you describe what Privacera is and the story behind it?













































Let's personalize your content