
How to test PySpark code with pytest
Start Data Engineering
APRIL 22, 2024
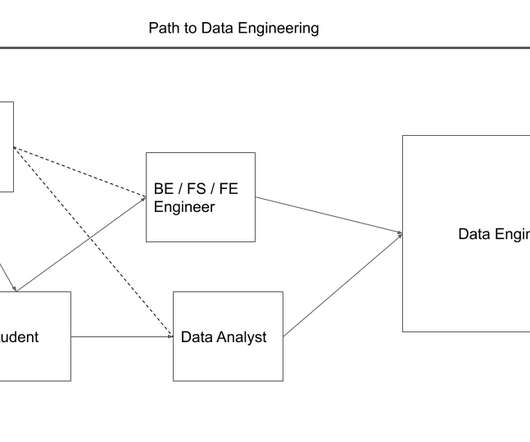
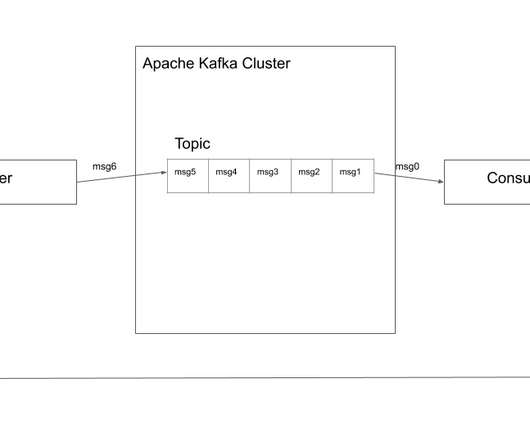
1. Introduction 2. Ensure the code’s logic is working as expected with tests 2.1. Test types for data pipelines 2.2. pytest: A powerful Python library for testing 2.2.1. Set context, run code, check results & clean up 2.2.2. Tests are identified by their name 2.2.3. Use fixture to create fake data for testing 2.2.4. Define items to be shared among tests with conftest.
















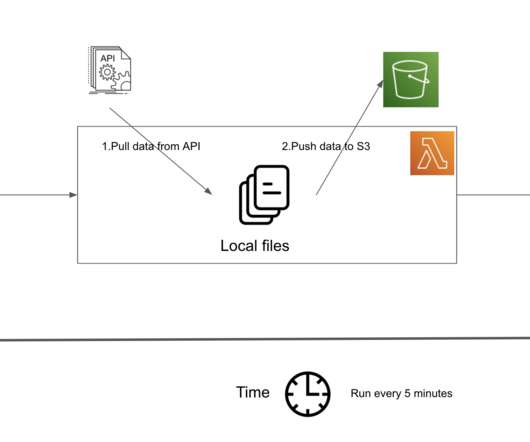






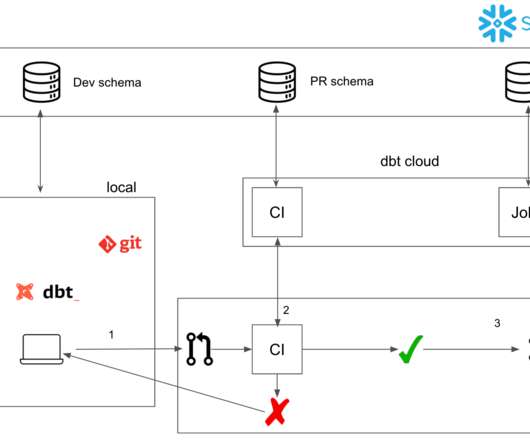









Let's personalize your content