

30+ Free Datasets for Your Data Science Projects in 2023
Knowledge Hut
NOVEMBER 28, 2023
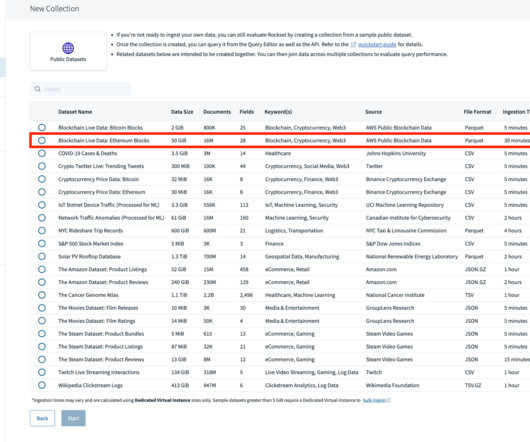
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. In this article, we will look at 31 different places to find free datasets for data science projects. What is a Data Science Dataset?






















Let's personalize your content