
How to Design a Modern, Robust Data Ingestion Architecture
Monte Carlo
MAY 28, 2024
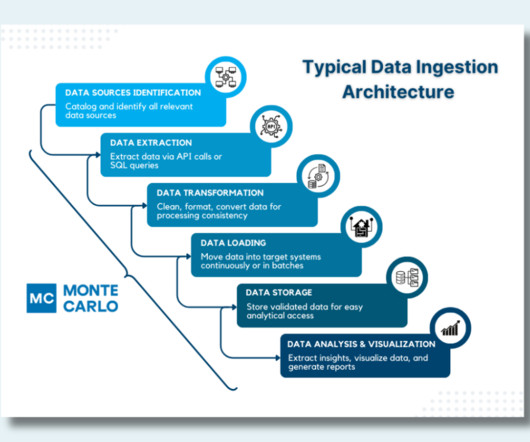
Common Tools Data Sources Identification with Apache NiFi : Automates data flow, handling structured and unstructured data. Used for identifying and cataloging data sources. Data Storage with Apache HBase : Provides scalable, high-performance storage for structured and semi-structured data.



























Let's personalize your content