
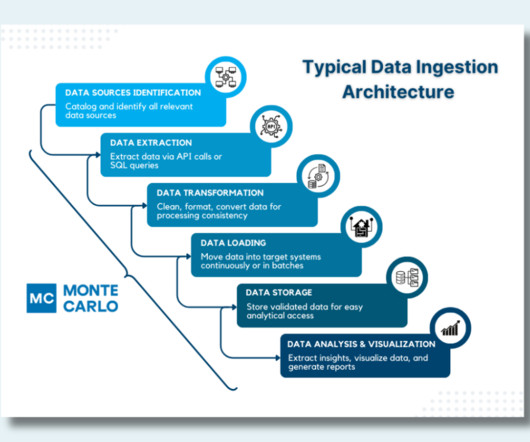
How to Design a Modern, Robust Data Ingestion Architecture
Monte Carlo
MAY 28, 2024
Batch Processing Tools For batch processing, tools like Apache Hadoop and Spark are widely used. Hadoop handles large-scale data storage and processing, while Spark offers fast in-memory computing capabilities for further processing. Data Extraction: Apache Kafka and Apache Flume handled real-time streaming data.













































Let's personalize your content