

Data News — Week 24.08
Christophe Blefari
FEBRUARY 23, 2024
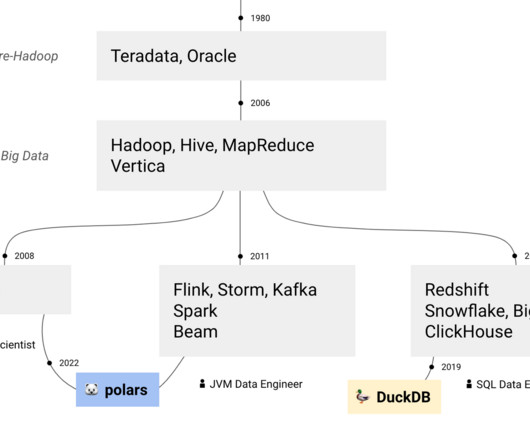
JVM vs. SQL data engineer — There's a big discussion in the community about what real data engineering is. Is it DataFrames or SQL? Still, I prefer SQL/Python data engineering, as you know me. I did not read the paper except the introduction and a the first schema, but it looks like awesome. PyIceberg 0.6.0:











































Let's personalize your content