

Mastering the Art of ETL on AWS for Data Management
ProjectPro
FEBRUARY 16, 2023
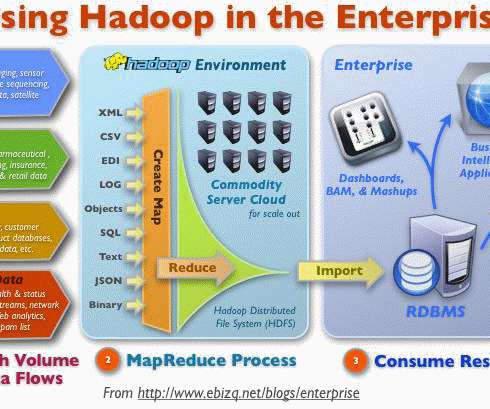
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. Data integration with ETL has changed in the last three decades.

















Let's personalize your content