
Fine-Tuning Improves the Performance of Meta’s Code Llama on SQL Code Generation
Snowflake
AUGUST 25, 2023
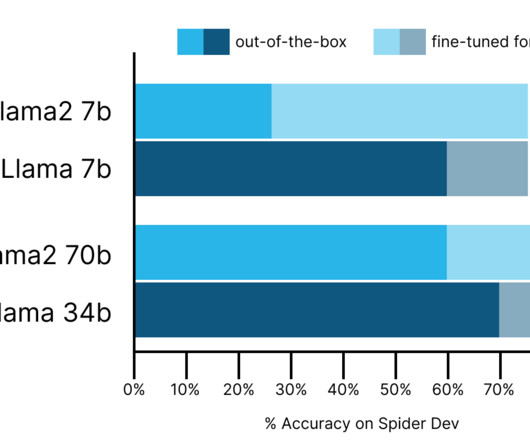
Code Llama models outperform Llama2 models by 11-30 percent-accuracy points on text-to-SQL tasks and come very close to GPT4 performance. SQL—the standard programming language of relational databases—was not included in these benchmarks. We tested the out-of-the-box SQL performance of Code Llama before fine-tuning our own version.

















Let's personalize your content